オリジナルRAGのWebアプリ化
今回は、前回「オリジナルRAG開発」にて生成したデータベースを利用して、Webアプリ化を実装していきます。
おすすめ記事
アプリ化する為に一連のコードをmain処理として下記のコード化を行い、app.pyとして保存します。
from langchain.chains import RetrievalQA
from langchain.schema import (SystemMessage, HumanMessage, AIMessage)
from langchain_google_genai import ChatGoogleGenerativeAI, GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import FAISS
import os
import streamlit as st
from langchain.prompts import ChatPromptTemplate
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.prompts import PromptTemplate
def load_db(embeddings):
return FAISS.load_local('faiss_store', embeddings, allow_dangerous_deserialization=True)
def init_page():
st.set_page_config(
page_title='オリジナルチャットボット',
page_icon='🧑💻',
)
def main():
embeddings = GoogleGenerativeAIEmbeddings(
model="models/embedding-001"
)
db = load_db(embeddings)
init_page()
llm = ChatGoogleGenerativeAI(
model="gemini-1.5-flash",
temperature=0.0,
max_retries=2,
)
# オリジナルのSystem Instructionを定義する
prompt_template = """
あなたは、「神風」サイトの岡田茂吉論文のチャットボットです。
背景情報を参考に、質問に対して岡田茂吉になりきって、質問に回答してくだい。
岡田茂吉論文に全く関係のない質問と思われる質問に関しては、「岡田茂吉論文に関係することについて聞いてください」と答えてください。
以下の背景情報を参照してください。情報がなければ、その内容については言及しないでください。
# 背景情報
{context}
# 質問
{question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=db.as_retriever(search_kwargs={"k": 2}),
return_source_documents=True,
chain_type_kwargs={"prompt": PROMPT}# システムプロンプトを追加
)
if "messages" not in st.session_state:
st.session_state.messages = []
if user_input := st.chat_input('質問しよう!'):
# 以前のチャットログを表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
print(user_input)
with st.chat_message('user'):
st.markdown(user_input)
st.session_state.messages.append({"role": "user", "content": user_input})
with st.chat_message('assistant'):
with st.spinner('Gemini is typing ...'):
response = qa.invoke(user_input)
st.markdown(response['result'])
#参考元を表示
doc_urls = []
for doc in response["source_documents"]:
#既に出力したのは、出力しない
if doc.metadata["source_url"] not in doc_urls:
doc_urls.append(doc.metadata["source_url"])
st.markdown(f"参考元:{doc.metadata['source_url']}")
st.session_state.messages.append({"role": "assistant", "content": response["result"]})
if __name__ == "__main__":
main()Webアプリをデプロイする
次にWebアプリをデプロイする方法を解説します。作成したチャットボットを実際にWebアプリとして公開するには、Streamlit Cloudを使用して簡単にデプロイが可能です。
①GitHubにコードとデータをアップロードする
作成したアプリケーションと前記事で生成されたデータベースをGitHubのリポジトリへアップロードします。
※GoogleColabで実行した場合は、データベース(faiss_store)とapp.pyアプリケーションファイルをダウンロードしリポジトリへアップロードします。
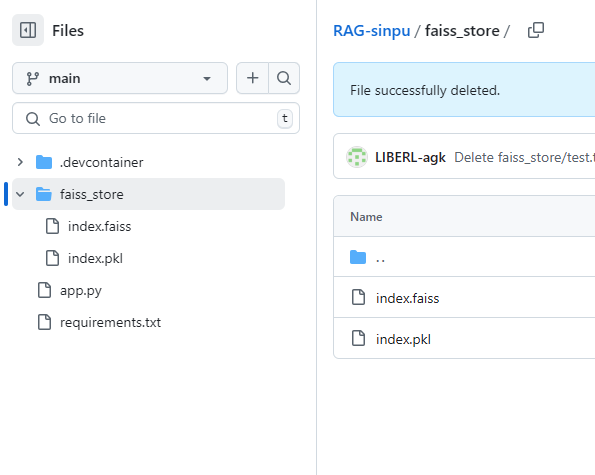
requirements.txtというファイルを作ってリポジトリ内に配置します。
streamlit
langchain
langchain_google_genai
faiss-cpu
langchain-community├── app.py # Streamlitアプリケーションのメインファイル
├── faiss_store/ # FAISSのベクトルストアデータ
│ ├── index.faiss # ベクトルデータを格納したFAISSインデックスファイル
│ ├── index.pkl # メタデータを格納したピクルファイル(ドキュメント情報)
├── requirements.txt # 必要なライブラリ一覧
└── README.md # プロジェクトの概要説明(任意)※構造は上記のようになります。
②Streamlit Cloudへ接続する
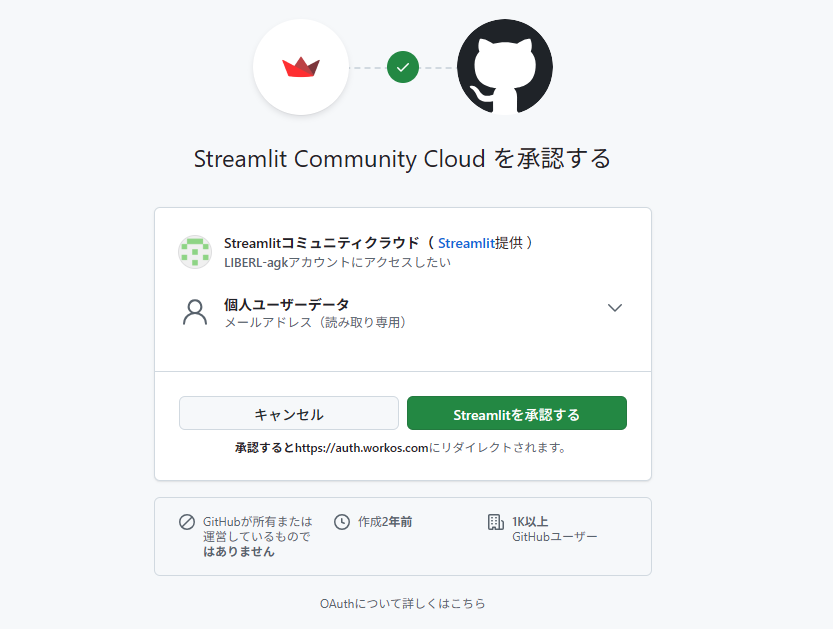
次に、Streamlit Cloudにアクセスして、GitHubのアカウントでサインインします。※プランはFreeプランを選択します

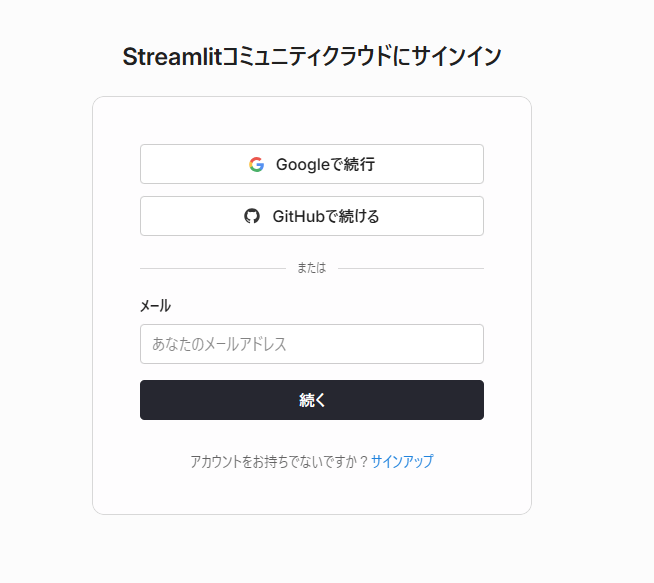
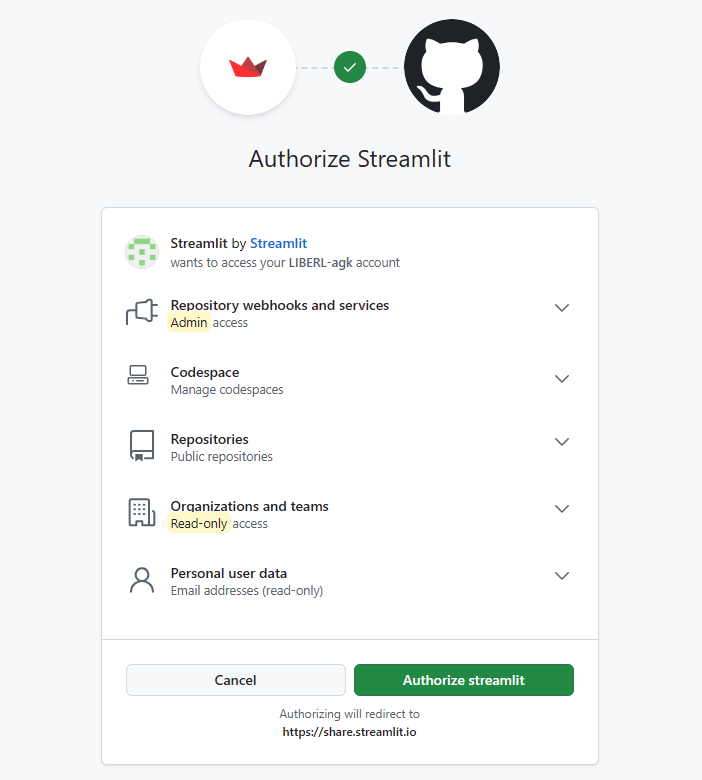
GitHubで続行を選択し、Streamlit CloudへGitHub内へのアクセス権限を付与します
③Streamlit Cloudへアプリ登録する
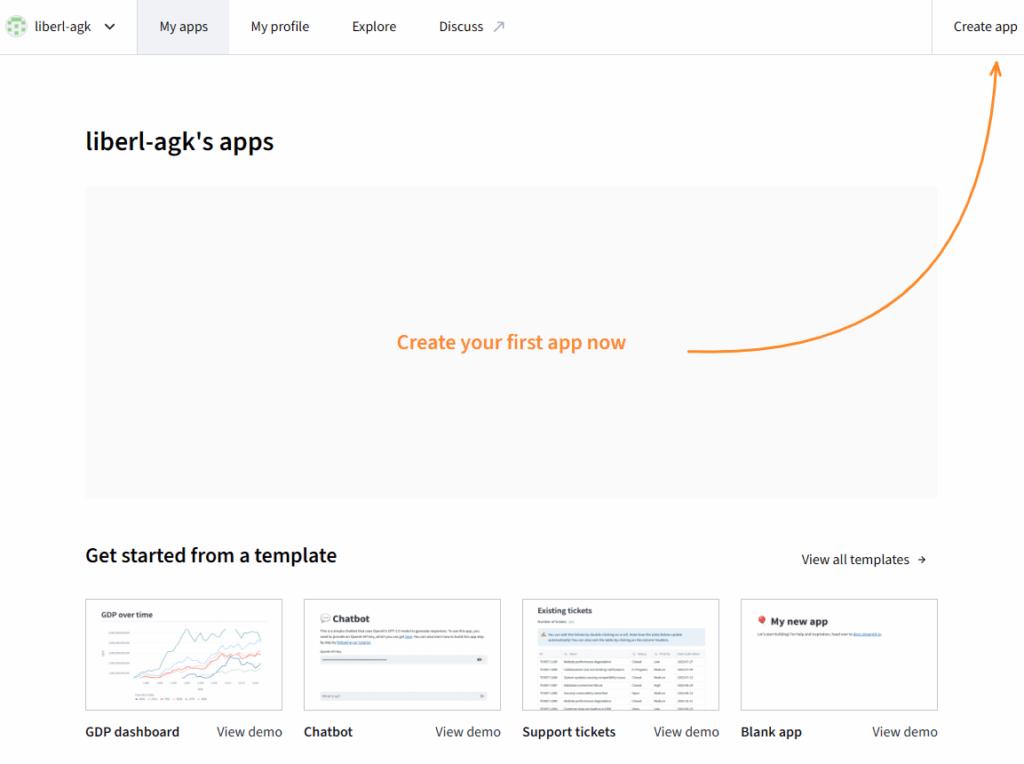
接続完了後、GitHub内のapp.pyアプリケーションをアプリとして登録します
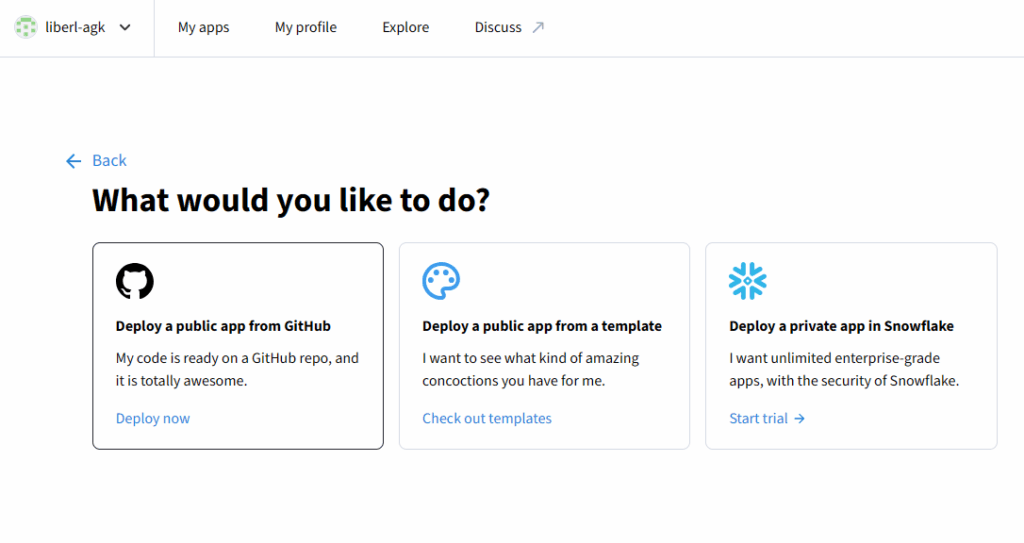
「Deploy a public app from GitHub」を選択し、アプリ設定を行います
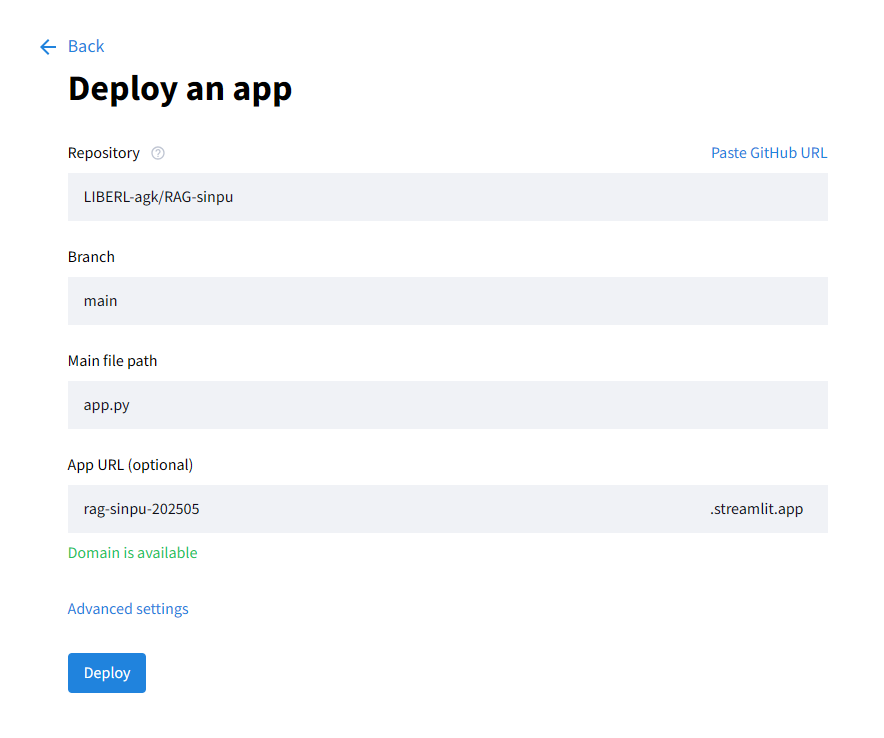
- Repository:app.pyのあるリポジトリ
- Branch:対象のブランチ
- Main file path:対象のアプリケーションファイル
- App URL:Webアプリの公開URL ※適時修正可能
④詳細設定にてGoogle API Keyを設定する
llmへの接続用としてAdvanced settingにてGoogle API Keyを設定します。作成してしまった後からでも登録可能です。
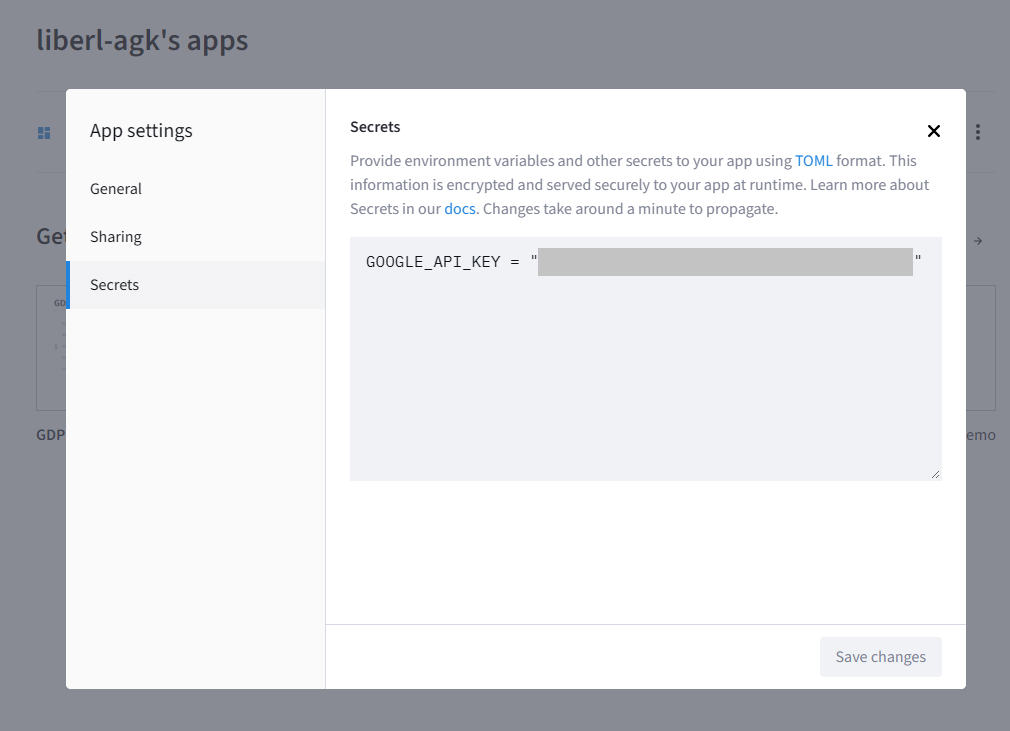
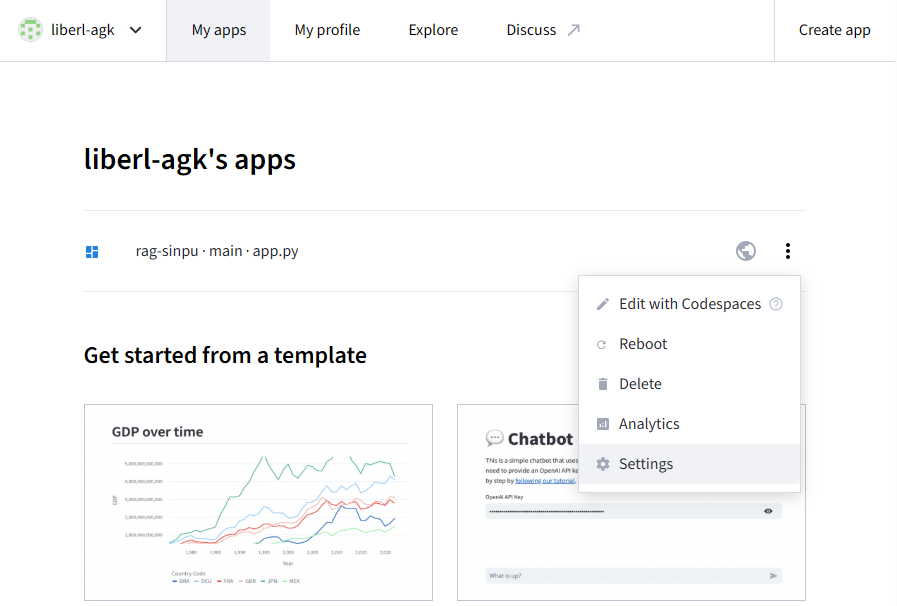
※作成後に設定する場合には、My Appsの一覧右メニュー「Settings」より設定可能です。設定したURLからだれでもそのチャットボットを使うことができるようになります。
※変更もGitHubにあげている内容を変更して、以下の画面でRebootを押すだけで変更できます。
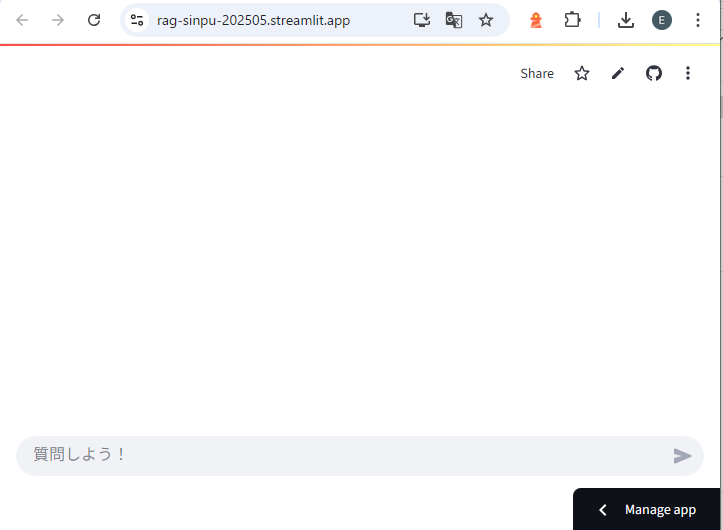
⑤アプリURLへ接続する
API Keyが設定できた段階で公開アプリは完成です
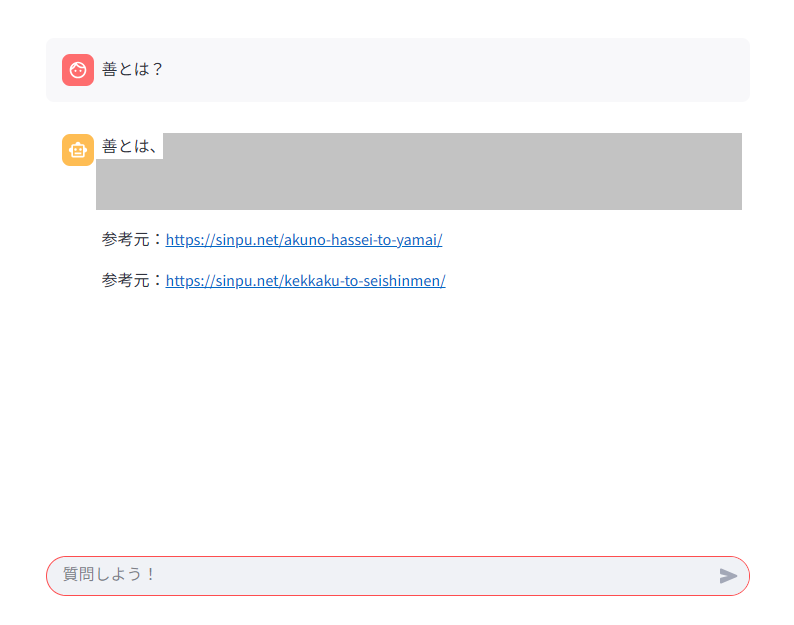
まとめ
今回の記事では、Streamlitを使ってWebアプリとしてデプロイするまでの一連の流れを解説しました。前記事よりAI作成~公開まで、全体のプロセスを体験することができたと思います。
RAGは、シンプルなFAQシステムを超えて、ユーザーの質問に対してより自然で具体的な応答を提供する強力なツールです。特に、特定のドメインに関連する情報を提供する場合に非常に有効です。
改善していくためには、データの追加やより高度なプロンプト設計の調整を試みてください。他のAIモデルや検索エンジンと組み合わせることで、より多機能なアプリケーションの構築も視野に入れられるでしょう。
ぜひ今後も、さまざまなユースケースに応用して、新たな挑戦に取り組んでみてください。